Database servers are key parts of any web project’s infrastructure and with the project’s increasing in size the database grows in significance. Sooner or later, however, we come to a point where database performance requirements can no longer be solved by the mere addition of extra memory and processor improvements. Increasing resources within one server has its limits and eventually, it becomes necessary to distribute the load among multiple servers.
Before implementing such a step, it is more than appropriate to clarify, what it is that we aim to accomplish. Some load distribution models will only allow us to manage an increase in the number of requests while others can also solve the issue of potential unavailability of one of the machines.
Scaling, High Availability, and Other Important Terms
First of all, let’s take a look at the basic terms we’ll be needing today. There are not many of them but without their knowledge, we won’t be able to move on. Experienced scalers can feel free to skip this section.
Scalability
The ability of a system (in our case a database environment) to react to increased or decreased resource need. In practice, we distinguish between two basic types of scaling: vertical and horizontal.
In the case of vertical scaling, we increase the resources the given database has at its disposal. Typically, this means adding accessible server memory and increasing the number of cores. Practically any application can be scaled vertically but sooner or later we run into hardware limits of the platform.
An alternative to this is horizontal scaling where we increase the performance of the application by adding more servers. This way we can increase the application’s performance almost limitlessly, however, the application must account for this kind of distribution.
High Availability
The ability of a system to react to a part of that system being down. The prerequisite for high availability is the ability to run the application in question in multiple instances.
The other instances can be fully replaceable and process requests in parallel (in this case we’re talking about active-active setup) or they can be in standby mode, where they only mirror data but aren’t able to process requests (so-called active-passive setup). Should a problem occur, one of the instances in passive mode is selected and turned into an active one.
Master node
The driving component of the system. In the case of databases, the master node is an instance operating in both read and write mode. If we have multiple full-featured master nodes, we speak of a so-called multi-master setup.
Slave node
A backup copy of data. In a standard situation, it only mirrors data and operates only in read mode. In the event of a master node failure, one of the slave nodes is selected and turned into a master node. Once the original master node is operational again, the new master will either return to being a slave node or it remains to be the master and the original master becomes a slave node.
Asynchronous replication
After inserting data into the master node, this insertion is confirmed to the client and written into the transaction log. At a later time, this change is replicated to slave nodes. Until the replication is completed, the new or changed data is only available on the master node and should it fail they would become inaccessible. Asynchronous replication is typical for MySQL.
Synchronous replication
The data insertion is confirmed to the client only after the data is saved to all nodes in the cluster. The risk of new data loss is eliminated in this case (the data is either changed everywhere or nowhere) but the solution is significantly more prone to issues in the network connecting the nodes.
Should the network be down, the performance of the cluster becomes temporarily downgraded. Alternatively, the reception of new requests for data change may even become temporarily suspended. This type of replication is used in the case of multi-master setups in combination with the Galera plugin.
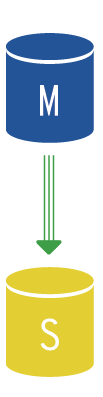
Master-Slave Replication
Master-slave is the basic type of database cluster replication. In this setup, there is a single master node that receives all request types. The slave node (or multiple slave nodes) mirror changes using asynchronous replication. Slave nodes don’t necessarily have the newest copy of the data at their disposal.
Should the master node fail, the slave node with the newest data copy is selected to become the new master. Each slave node evaluates how delayed it is compared to the master node. This value can be found within the Seconds_behind_master variable and it is essential to monitor it. An increasing value indicates an issue in change replication at the master node.
The slave node operates in a read-only mode and can thus deal with select type requests. In this case, we’re talking about the so-called read/write split, which we’ll discuss in a moment.
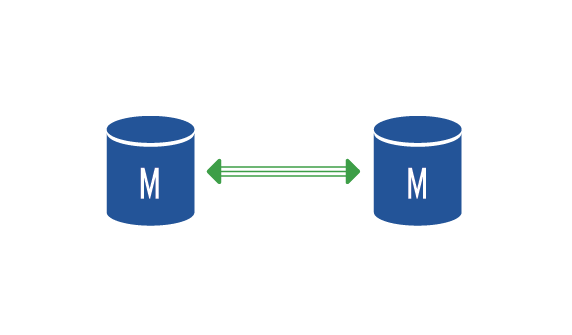
Master-Master Replication
Master-master setup is such where we have two master nodes. Both are able to deal with all types of requests but between the two of them, asynchronous replication is the modus operandi. This presents a disadvantage when the data inserted into one node may not be immediately accessible from the second one. In practice, we set this up in such a way, so that each node is also a slave node to the other.
This setup is advantageous when we install a load balancer before the MySQL servers, which directs half of the connections to each machine. Each node is a separate master at the same time and knows not the other server is a master too. It is, therefore, necessary to set up the auto-increment step to the value of 2. If we don’t do this, a collision of primary keys that use auto-increment will ensue.
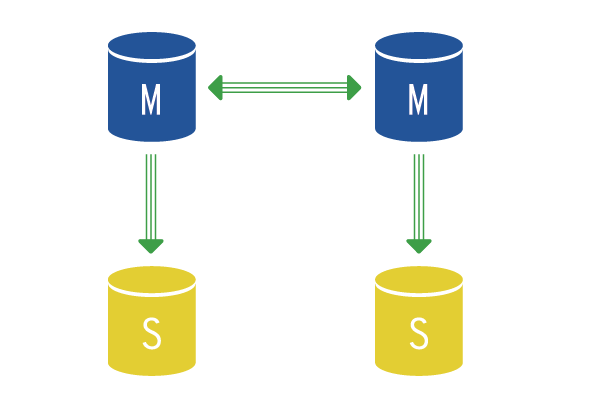
Each of the master nodes can have additional slave nodes that can be used for data reading (read/write split) and as a backup.
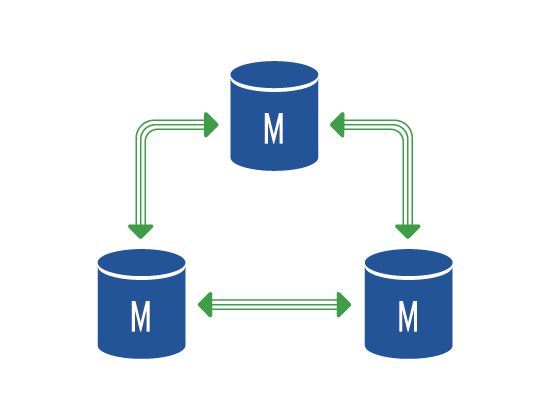
Multi-Master Replication
If there are more than two master nodes in a cluster, we’re talking about a multi-master setup. This setup cannot be built in basic MySQL but an implementation of the wsrep protocol, e.g. Galera, has to be used.
Wsrep implements synchronous replication and as such is very sensitive to network issues. In addition, it requires time synchronization of all nodes. On the other hand, it allows for all request types to be sent to all nodes in the cluster which makes it very suitable for a load balancing solution. A disadvantage being that all replicated tables have to use the innodb engine. Table utilizing a different engine will not be replicated.
Sharding
Sharding is dividing the data into logical segments. In MySQL, the term partitioning is used to describe this type of data storage and in essence, this means that the data of a single table is divided among several servers, tables or data files within a single server.
Data sharding is appropriate, if the data we have, forms separate groups. Typical examples are historical records (sharding according to time) or user data (sharding according to user ID). Thanks to such data division, we can effectively combine different storage types where we store the most recent data on fast SSD discs and older data that we don’t expect to be used very often on cheaper rotation discs.
Sharding is very often used in NoSQL databases, e.g. ElasticSearch.
Read-Write Splitting
In the Master-Slave replication mode, we have the performance of slave nodes at our disposal but cannot use it for write operations. However, if we have an application where most of the requests are just selects (typical in web projects), we can use their performance for read operations. In this case, the application directs write operations (insert, delete, update) to the master node but sends selects to the group of slave nodes.
Thanks to the fact that a single master node can have many slave nodes, this read/write splitting will help us increase the response rate of the entire application by distributing the read operations.
This behavior doesn’t require any configuration on the side of the database server but it needs to be dealt with in the application side. The easiest option is to maintain two connections in the application: one for read and one for write operations. The application then decides on which connection to use for every given request based on its type
The second option, which is useful if we are unable to implement read/write splitting at the application level, is using application proxy that understands requests and is able to automatically send them to appropriate nodes. The application then maintains only one connection to the proxy and doesn’t concern itself with request types. A typical example of this solution is Maxscale. Unfortunately, this is a commercial product but it provides a free version limited to three database nodes.
We Scale for You
Don't have the capacity to maintain and scale you databases? We'll do it for you.
We will take care of even very complex maintanance and optimization of a wide range of databases. We'll ensure their maximum stability, availibility, and scalability. Our admin team manages tens of thousands of database servers and cluster so you'll be in the hands of true experts.